UnderScore: Musical Underlays for Audio Stories
Steve Rubin, Floraine Berthouzoz, Gautham Mysore, Wilmot Li, Maneesh Agrawala
Abstract
Audio producers often use musical underlays to emphasize key moments in spoken content and give listeners time to reflect on what was said. Yet, creating such underlays is time-consuming as producers must carefully (1) mark an emphasis point in the speech (2) select music with the appropriate style, (3) align the music with the emphasis point, and (4) adjust dynamics to produce a harmonious composition. We present UnderScore, a set of semi-automated tools designed to facilitate the creation of such underlays. The producer simply marks an emphasis point in the speech and selects a music track. UnderScore automatically refines, aligns and adjusts the speech and music to generate a high-quality underlay. UnderScore allows producers to focus on the high-level design of the underlay; they can quickly try out a variety of music and test different points of emphasis in the story. Amateur producers, who may lack the time or skills necessary to author underlays, can quickly add music to their stories. An informal evaluation of UnderScore suggests that it can produce high-quality underlays for a variety of examples while significantly reducing the time and effort required of radio producers.
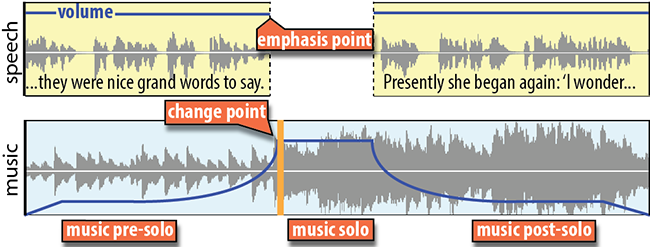
A musical underlay highlights an emphasis point in an audio story. The music track contains three segments; (1) a music pre-solo that fades in before the emphasis point, (2) a music solo that starts at the emphasis point and plays at full volume while the speech is paused, and (3) a music post-solo that fades down as the speech resumes. At the beginning of the solo, the music often changes in some significant way (e.g. a melody enters, the tempo quickens, etc.) Aligning this change point in the music with a pause in speech and a rapid increase in the music volume further draws attention to the emphasis point in the story.