Strategies for Crowdsourcing Social Data Analysis
Wesley Willett, Jeffrey Heer, Maneesh Agrawala
Abstract
Web-based social data analysis tools that rely on public discussion to produce hypotheses or explanations of the patterns and trends in data, rarely yield high-quality results in practice. Crowdsourcing offers an alternative approach in which an analyst pays workers to generate such explanations. Yet, asking workers with varying skills, backgrounds and motivations to simply "Explain why a chart is interesting" can result in irrelevant, unclear or speculative explanations of variable quality. To address these problems, we contribute seven strategies for improving the quality and diversity of worker-generated explanations. Our experiments show that using (S1) feature-oriented prompts, providing (S2) good examples, and including (S3) reference gathering, (S4) chart reading, and (S5) annotation subtasks increases the quality of responses by 28% for US workers and 196% for non-US workers. Feature-oriented prompts improve explanation quality by 69% to 236% depending on the prompt. We also show that (S6) pre-annotating charts can focus workers' attention on relevant details, and demonstrate that (S7) generating explanations iteratively increases explanation diversity without increasing worker attrition. We used our techniques to generate 910 explanations for 16 datasets, and found that 63% were of high quality. These results demonstrate that paid crowd workers can reliably generate diverse, high-quality explanations that support the analysis of specific datasets.
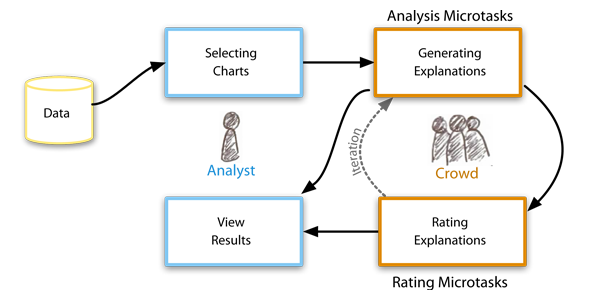
In our analysis workflow an analyst first selects charts, then uses crowd workers to carry out analysis microtasks and rating microtasks to generate and rate possible explanations of outliers, trends and other features in the data. Our approach makes it possible to quickly generate large numbers of good candidate explanations for outliers and trends in data.